1. 概述
XML(Extensible Markup Language)中文译为可扩展标记语言,它是一种简单、灵活、易扩展的文本格式,它主要关注数据内容,常用来传送、存储数据。
当通过 XML 来传送数据时,自然会涉及到 XML 的解析工作,通常 Python 可以通过如下三种方式来解析 XML:
-
DOM DOM 方式会将整个 XML 读入内存,在内存中解析成一个树,通过对树的操作来操作 XML,该方式占用内存较大,解析速度较慢。
-
SAX SAX 方式逐行扫描 XML 文档,边扫描边解析,占用内存较小,速度较快,缺点是不能像 DOM 方式那样长期留驻在内存,数据不是长久的,事件过后,若没保存数据,数据会丢失。
-
ElementTree ElementTree 方式几乎兼具了 DOM 方式与 SAX 方式的优点,占用内存较小、速度较快、使用也较为简单。
2. 写入
首先,我们通过 Python 创建一个 XML 文档并向其中写入一些数据,实现代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from xml.etree import ElementTree as et
import xml.dom.minidom as minidom
# 创建根节点
root = et.Element('school')
names = ['张三', '李四']
genders = ['男', '女']
ages = ['20', '18']
# 添加子节点
student1 = et.SubElement(root, 'student')
student2 = et.SubElement(root, 'student')
et.SubElement(student1, 'name').text = names[0]
et.SubElement(student1, 'gender').text = genders[0]
et.SubElement(student1, 'age').text = ages[0]
et.SubElement(student2, 'name').text = names[1]
et.SubElement(student2, 'gender').text = genders[1]
et.SubElement(student2, 'age').text = ages[1]
# 将根目录转化为树行结构
tree = et.ElementTree(root)
rough_str = et.tostring(root, 'utf-8')
# 格式化
reparsed = minidom.parseString(rough_str)
new_str = reparsed.toprettyxml(indent='\t')
f = open('test.xml', 'w', encoding='utf-8')
# 保存
f.write(new_str)
f.close()
看一下效果:
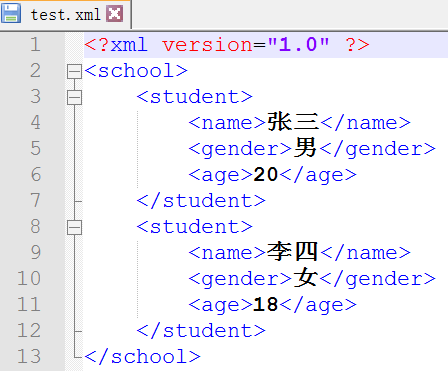
3. 解析
我们分别使用 DOM、SAX、ElementTree 方式解析上面生成的 XML 文件。
3.1 DOM 方式
看一下如何通过 DOM 方式进行解析,实现代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from xml.dom.minidom import parse
# 读取文件
dom = parse('test.xml')
# 获取文档元素对象
elem = dom.documentElement
# 获取 student
stus = elem.getElementsByTagName('student')
for stu in stus:
# 获取标签中内容
name = stu.getElementsByTagName('name')[0].childNodes[0].nodeValue
gender = stu.getElementsByTagName('gender')[0].childNodes[0].nodeValue
age = stu.getElementsByTagName('age')[0].childNodes[0].nodeValue
print('name:', name, ', gender:', gender, ', age:', age)
执行结果:
1
2
name: 张三 , gender: 男 , age: 20
name: 李四 , gender: 女 , age: 18
3.2 SAX 方式
看一下如何通过 SAX 方式进行解析,实现代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
import xml.sax
class StudentHandler(xml.sax.ContentHandler):
def __init__(self):
self.name = ''
self.age = ''
self.gender = ''
# 元素开始调用
def startElement(self, tag, attributes):
self.CurrentData = tag
# 元素结束调用
def endElement(self, tag):
if self.CurrentData == 'name':
print('name:', self.name)
elif self.CurrentData == 'gender':
print('gender:', self.gender)
elif self.CurrentData == 'age':
print('age:', self.age)
self.CurrentData = ''
# 读取字符时调用
def characters(self, content):
if self.CurrentData == 'name':
self.name = content
elif self.CurrentData == 'gender':
self.gender = content
elif self.CurrentData == 'age':
self.age = content
if (__name__ == "__main__"):
# 创建 XMLReader
parser = xml.sax.make_parser()
# 关闭命名空间
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = StudentHandler()
parser.setContentHandler(Handler)
parser.parse('test.xml')
执行结果:
1
2
3
4
5
6
name: 张三
gender: 男
age: 20
name: 李四
gender: 女
age: 18
3.3 ElementTree 方式
看一下如何通过 ElementTree 方式进行解析,实现代码如下所示:
1
2
3
4
5
6
7
import xml.etree.ElementTree as et
tree = et.parse('test.xml')
# 根节点
root = tree.getroot()
for stu in root:
print('name:', stu[0].text, ', gender:', stu[1].text, ', age:', stu[2].text)
执行结果:
1
2
name: 张三 , gender: 男 , age: 20
name: 李四 , gender: 女 , age: 18
欢迎微信搜索 Python小二,第一时间阅读、获取源码,回复关键字 1024 可以免费领取个人整理的各类编程语言学习资料。